Kubernetes Controller for OAuth Proxy Automation
In this post, I’ll walk through a project I worked on in the spirit of picking up the pen again. It’s a story about friction in day-to-day operations, and how a small but targeted solution helped eliminate an entire class of manual, error-prone work.
Problem
When I joined my current company a couple years ago, one of the first issues I ran into was an operational gap around OAuth for internal applications within Kubernetes. Internal apps were secured with oauth2-proxy, backed by Okta as the identity provider. All clusters shared a single Okta app with an allowlist of redirect URIs.
This setup worked fine in steady state, but changes were painful and manual:
- Adding a new app → redirect URIs needed to be added for every cluster where the app ran, e.g.
grafana.k8s-1.prod.example.comandgrafana.k8s-2.prod.example.com. - Cluster failover → required removing URIs for each application for the old cluster and adding URIs for the new one.
- App decommission → required manually removing all its redirect URIs.
To make things worse, each app usually had multiple URIs:
- One per Kubernetes cluster, e.g.
grafana.k8s-1.prod.example.comandgrafana.k8s-2.prod.example.com. - One load-balanced URI across a group of clusters, e.g.
grafana.k8s.prod.example.com. - Sometimes, additional custom URIs, e.g.
grafana.example.com.
We never upgraded k8s clusters in place, instead opting to stand up a new cluster and fail over to it. The result was lots of manual work, lots of opportunities for mistakes, and a constant trail of dead redirect URIs or broken logins after cluster failovers.
I decided to solve this problem as one of my first contributions.
Solution
The goal: no manual Okta configuration.
I built a Kubernetes controller, the okta-oauth-controller, to automate the process.
It runs in each cluster, monitors ingresses with a specific label, and manages the corresponding redirect URIs in Okta.
Why per-cluster apps?
At first, I thought we could keep the shared Okta app. However, Okta’s API only allows you to overwrite the entire list of redirect URIs, not add or remove individual ones. That meant controllers in different clusters would constantly step on each other.
Rather than introducing cross-cluster coordination or a central locking service, I took a simple approach: one dedicated Okta app per cluster. This provided clean isolation and made implementation of the reconciliation loop straightforward: each controller just overwrites the list of redirect URIs for its own cluster in an edge-triggered, level-driven way.
OAuth Proxy configuration
Because all clusters used a shared Okta app, OAuth Proxy configuration was identical in all clusters and could be deployed easily as a k8s secret along with the proxy itself. With an Okta app per cluster, the configuration (client ID, client secret) differs per cluster. For this reason, the responsibility for managing the secret containing the OAuth Proxy configuration was moved to the okta-oauth-controller.
Implementation
I scaffolded the controller using kubebuilder which I had already used to implement a controller before. The high-level logic looks like this:
- Startup checks
- Ensure an Okta app exists for the cluster (create if missing).
- Ensure the OAuth2 Proxy secret exists (create if missing, pulling values from Okta).
- Reconciliation loop
- Triggered by startup, ingress changes, and periodic syncs.
- Gather all labeled ingresses.
- Build the desired list of redirect URIs.
- Overwrite the Okta app configuration with the new list.
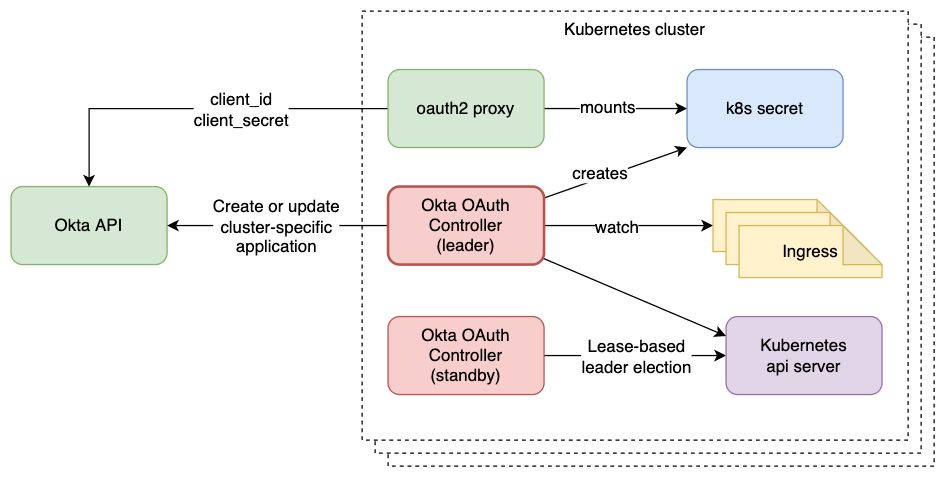
This also solved the OAuth Proxy secret distribution problem. Instead of reusing a static secret across clusters, the controller creates the secret with fresh values (client ID, client secret) at cluster startup. OAuth2 Proxy pods won’t start until the secret exists because it mounts the secret, so the dependency ordering is naturally enforced.
Migration
Migrations should be safe, gradual, and reversible.
Here’s how I approached it:
- Deploy controllers → rolled out
okta-oauth-controllercluster by cluster, monitoring Okta API usage and validating redirect URIs. - Dual OAuth2 Proxies → deployed a second OAuth Proxy per cluster, wired up to the new per-cluster Okta apps.
- Gradual switchover → slowly updated ingresses to use the new proxies, with plenty of baking time and monitoring for regressions.
- Clean up → once all traffic was cut over, removed the original OAuth Proxy deployment.
The riskiest step was ingress migration, since a mistake could lock engineers out of secured apps. The gradual approach paid off: no major incidents.
Challenges
A few interesting challenges came up:
-
Cross-cluster load balancing Apps using URIs that balanced traffic across clusters broke initially. Each cluster had a unique cookie secret, so cookies weren’t accepted when requests landed on a different cluster. The fix: use a shared cookie secret per AWS account.
-
Okta SDK limitations The Okta Go SDK was missing endpoints (like fetching client secrets) and had undocumented caching behavior. I had to drop down to raw HTTP calls for missing endpoints and dig through source code to figure out how to disable caching.
Day Two Operations
Looking back after a couple of years, the controller has held up well. Some operational lessons:
-
Deployment tooling Kubebuilder scaffolds with kustomize, but we were using helm. Translating configs was annoying. Today there’s a helm plugin for kubebuilder that cloud have saved time, although I haven’t tested it yet.
-
Cluster lifecycle When a cluster is decommissioned, ingresses are deleted, which triggers
okta-oauth-controllerto clean up redirect URIs automatically. However, the per-cluster Okta app is never deleted as I deemed that too risky and unecessary. -
GitOps compatibility We used helmfile initially, then moved to ArgoCD. Both worked fine as the natural dependency ordering ensured OAuth2 Proxy only started once the controller had created its config secret.
-
Metrics We tracked Okta API request counts to ensure we weren’t pushing limits.
Conclusion
What started as an operational annoyance turned into a robust, low-maintenance automation.
The okta-oauth-controller eliminated manual Okta management, reduced error rates, and improved cluster isolation. The migration plan allowed us to roll it out safely without downtime, and the design has scaled well over time.
It’s a good reminder that sometimes the best infrastructure work isn’t glamorous. It’s finding the friction in daily operations and automating it away.